In today’s fastidious world when Internet has taken over everything, it is hard to walk out of your homes and invest in a business. With the ease and availability of technological services, one is able to become an entrepreneur from their houses, starting a new business and conquering the world. Online sales through various websites and one’s own have become everyone’s cup of tea.
But, is your business leading you anywhere? It is always important to keep track of your progress so that you can meet the needs of your customers.
For amateur entrepreneurs, it could be difficult to track their achievements and progress. So, we have brought you a list of Key Performance Indicators (KPIs) to kick-start your business and establish it further.
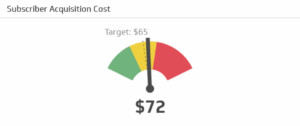
AVERAGE ACQUISITION COST
One of the most vital e-commerce metrics, AAC measures how much the cost could be to gain a new customer. For acquiring a profit, one must keep track of the acquisition channels. This ensures you pay for quality traffic and keeps your expenses under control.
Keep track and analyze all your forums- social media, websites, ads etc. and keep a note as to which particular forum makes a difference to your business and brings more revenue. It is very important to spend your budget in the right marketing forum to ensure a greater profit.
CUSTOMER LIFETIME VALUE
CLV measures how much time your customer spends on your online website/shop in the complete customer lifecycle.
CLV= REVENUE EARNED FROM CUSTOMER – ACQUISITION COST
This could be a little complicated but it is important to keep customer behavioral psychology in mind, examine and analyze their behaviors.
You can also track your past offers that worked positively for the website, customers and also had boosted your revenue.
AVERAGE ORDER VALUE
CLV is yet related to another metric- the Average Cost Value (ACV).
ACV is an efficient way to increase customers/traffic on your websites.
This also ensures to note how many customers genuinely want your products and are ready to purchase them anytime. Ways to get more customers/traffic on your e-commerce website:
- Value offers
- Incentives
- Discounts
- Loyalty programs/offers
- Bonus points

CONVERSION RATE
The most vital e-commerce metric, Conversion Rate keeps the track on how many of your followers/website visitors actually convert into customers.
This, in turn, helps track the shopping experience you provide to your customers. Hence, conversion rate could help you to increase customer experience, provide offers/discounts/bonuses if necessary for the smooth running of your forum.
AVERAGE MARGIN
Average Margin is what your website is earning from each profit that you have enquired. In other words, it tracks what percentage of the retail price has been your profit.
It is advisable that you always keep the margin higher than the average acquisition cost. This ensures you have a healthy striving business and happy customers!

CART ABANDONMENT RATE
Statistics show that about 60-70% people abandon their carts online.
Some of the most common reasons are:
- High shipping costs
- Requirement for registration
- Free shipping not available
- Estimated delivery not quick enough
- Unavailability of many payment options
- Complicated checkout process
Some customers also abandon their carts because they are only there for the visual experience or “window shopping” and do not intend to shop.

REFUND AND RETURN RATE
In e-commerce business, especially in the online clothing business, refund and return are the primary functions; which if unavailable could cost you valuable customers and lower your profits.
It is important to keep track of the most returned products and advisable you remove them from your forum. It is important to keep the customer feedback in mind and work on meeting their demands and solving their problems. This ensures healthy business and rapport between the customer and the e-commerce website.
Frequent refunds/returns can, in turn, cost your image on the market forum and bring down your valuable profit and revenue.
How to avoid frequent refunds/returns?
- Photos uploaded should be under natural light conditions and from every possible angle.
- A Correct description of the product must be mentioned along with correct sizes.
- In the clothing industry, the material of the product engages maximum importance. Hence one should be careful while describing. Always mention the type and quality of clothing.
- One must also make sure that the quality of the product adheres to the price of the product mentioned.

SUPPORT RATE
It is easy to maintain a high support rate on an offline business but online, it gets a little too tricky. Support rate measures how many of your customers need the company’s support before purchasing products. If this is too high, then you must look into the product statistics and improve on the product or look into the complaints or frequently asked questions (FAQs)
For efficient growth of your e-commerce website make sure you keep all your communication portals open and free. Live chats, E-mail services, Toll-free numbers are some ways one can create communicative efficiency.
It is always better to attend and resolve customer problems and look into customer grievances. This ensures a good customer base and your reputation.
Some suggestions for a healthy customer relationship:
- Always address the customer. No matter how frustrated they seem, it always calms them down.
- Listen before you speak.
- Address the problem to the point.
- Always be polite.
- Try and solve the problem then and there.
- It’s okay to ask for customer feedback.

BEST PERFORMING PRODUCTS AND CATEGORIES
Some products on your e-commerce website may sell better compared to others. But there could be many other products that have the potential to be sold just as much but do not make it because of faulty or lack of correct advertisements.
This could lead you to lose important revenue.
Learn to sort out items. You could do that based on:
- Outdated items which are no longer viewed/encouraged by customers
- Items often bought together
- Group possible items that can be bought together
- Items that engage more sales
It is important to keep your bestsellers selling but it is also essential to make sure all your other products get the necessary exposure to your customer’s interest.

In today’s world when technology is overpowering the minds of business personnel, these e-commerce metrics are mentioned to make your lives easier and keep your business thriving. We understand the pain you take to settle your business and hence we lay our objectives towards giving you some ways and tips to ensure your business is running smooth and you enquire maximum profit.